
Data User Guide | Specification
In the specification phase, you build on the ideas developed during the ideation phase and turn them into clearly defined concepts. While the ideation phase focuses on generating and refining use cases, the specification phase helps you develop these ideas into more concrete and structured forms. The goal is to move from exploratory thinking to a clearer understanding of how data could be used in practice.
At this stage, you further develop your ideas in one of three possible directions. An idea may evolve into a data product, a data-driven service or a study, depending on its purpose, scope and intended application context. This distinction helps you clarify what kind of initiative you are developing and supports a more structured description of its characteristics and expected outcomes.
In this phase, you focus on sharpening the core concept. You define its purpose, scope and expected value more precisely and describe how the use of data contributes to the overall idea. Instead of generating new ideas, you deepen and consolidate the ones you already developed. By the end of this phase, you should have a clearly articulated concept that explains how data use translates into a concrete initiative and that can serve as a foundation for the following stages of planning and implementation.
Data product
A data product refers to a clearly defined data-based artifact that is intentionally designed and provided to fulfill a specific usage purpose. Rather than representing raw datasets, a data product emphasizes structured preparation, usability, and reusability of data for a defined audience. Data are therefore treated as a consumable entity that delivers value through purposeful design and management.
Within contemporary data architecture research, data products are conceptualized as domain-oriented, curated data assets that are aligned with specific use contexts and organizational needs (Dehghani, 2022). Similarly, data governance literature highlights the shift towards treating data as value-creating objects that are actively managed and structured to support decision making and operational processes (Otto, 2011).
In the specification phase, a data product represents an idea where the primary value emerges from the structured provision, integration, or preparation of data.
Data driven service
A data-driven service describes a service offering in which value creation is largely enabled through the continuous use and processing of data. In contrast to a data product, the focus lies not on the data artifact itself but on how data are embedded into an ongoing service process that supports actions, decisions, or interactions.
Research on data-driven service innovation emphasizes that digital services increasingly rely on data to dynamically adapt processes, personalize offerings, and generate new forms of organizational value (Lim & Maglio, 2018). Studies on smart service systems further underline that data serve as a central resource for creating responsive and context-aware services (Beverungen et al., 2019).
Within the specification phase, a data-driven service therefore represents an idea where data use becomes part of a continuous organizational service or operational activity.
Model Training
Model training describes scenarios in which data are primarily used to develop, train, validate, or refine predictive, classificatory, or generative models. In contrast to data products, where the dataset itself represents the central artifact, and data-driven services, where data are embedded into an ongoing service process, the primary output of model training is a trained analytical model.
Machine learning research defines model training as the process of fitting an analytical function to historical data in order to identify patterns and enable prediction or classification (Jordan & Mitchell, 2015; Hastie et al., 2009). In this context, data do not merely inform a decision process but actively shape the internal structure and parameters of the resulting model (Goodfellow et al., 2016). The trained model thereby becomes the primary artifact of value creation.
Within applied domains such as healthcare, the development of predictive models requires careful attention to data representativeness, training and validation procedures, and performance evaluation criteria (Beam & Kohane, 2018). Predictive modeling literature further emphasizes the conceptual distinction between explanatory data analysis and predictive model construction, highlighting the importance of explicitly defining modeling objectives and evaluation metrics (Shmueli, 2010).
Within the specification phase, model training therefore requires explicit clarification of:
- the modeling objective (e.g., prediction, classification, risk scoring),
- the required training and validation data,
- performance criteria and evaluation metrics,
- and the intended organizational embedding of the trained model.
In regulated environments such as the EHDS context, additional governance considerations arise, particularly regarding lawful access to training data and secure processing requirements.
Study
A study refers to a structured research activity that uses data to systematically investigate questions, generate insights, or test hypotheses. Unlike data products or data-driven services, the primary objective is not to create a persistent artifact or operational service but to produce knowledge through analysis.
Research design literature describes studies as methodologically guided processes that involve data collection, analysis, and interpretation to develop transparent and reproducible findings (Creswell & Creswell, 2018). Data therefore function as the basis for analytical inquiry rather than as a deliverable product or service.
Within the specification phase, a study represents an idea where data use is primarily oriented towards analytical exploration or research-driven objectives.
Action module: Categorize and specify
Categorize the ideas developed in the ideation phase according to their intended direction as a data product, a data-driven service, or a study. Select the corresponding template and continue working on the idea by further specifying its purpose, scope, and expected outcome. Use the template to gradually refine and structure the concept, building on the insights generated in the previous phases.
If multiple ideas have emerged, work on them in parallel by using separate templates for each concept. This allows different ideas to evolve independently while ensuring that each one is specified in a consistent and structured manner. The aim of this step is to move from a general idea towards a clearly articulated and concrete concept that reflects how data will be used.
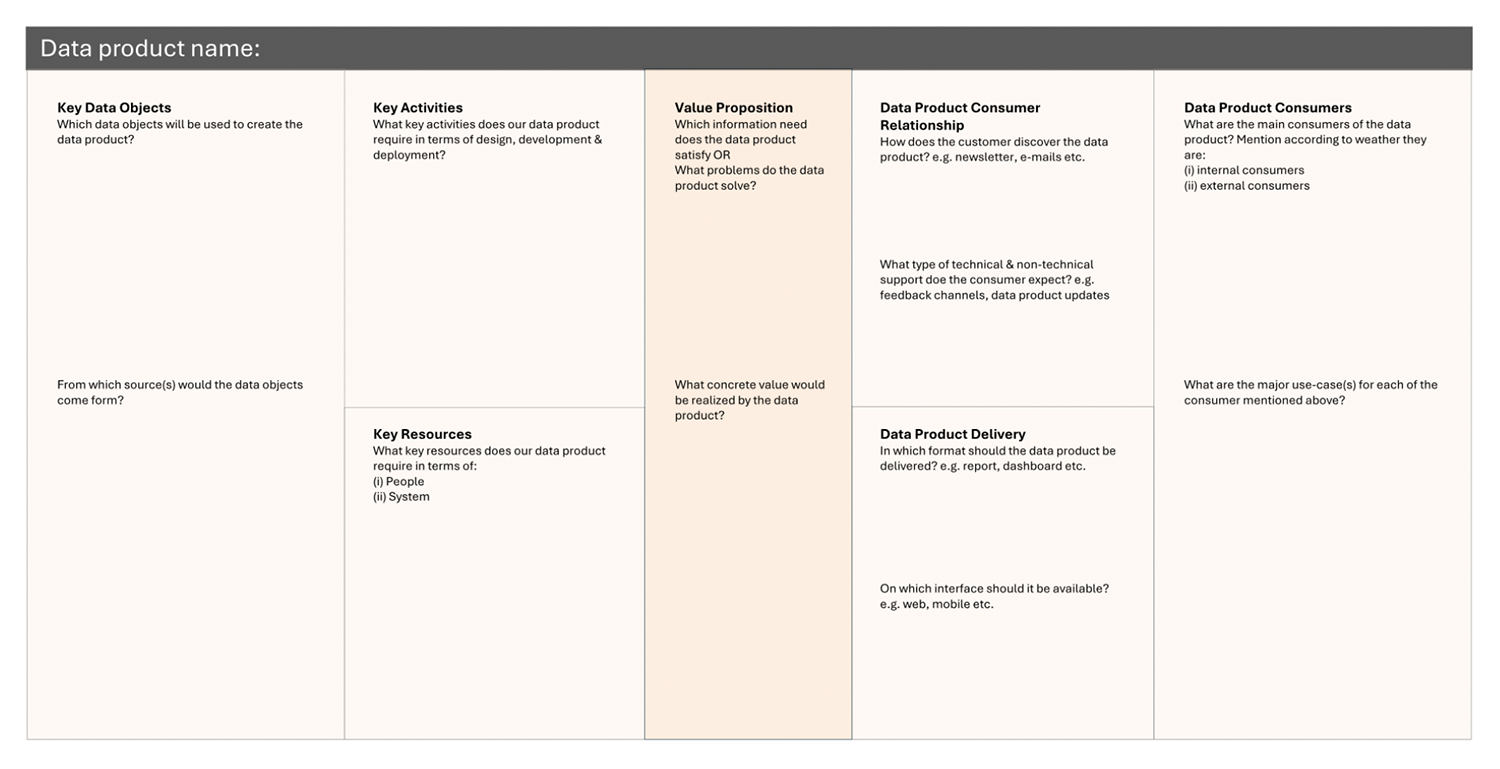
Data Product Canvas
Use this canvas to further specify and structure your data product idea. The goal is to gradually clarify how the data product creates value, who it serves, and what is needed to realize it. The structure of this canvas is adapted from the Data Product Canvas proposed by Hasan, Finkel, and Legner (2025).
Start by defining the key data objects and their sources to understand the data foundation of your idea. Then describe the key activities and resources required to design, develop, and maintain the data product. Focus on outlining the main elements rather than technical detail.
Next, formulate the value proposition by explaining which information needs are addressed and what concrete value the data product creates. Identify the data product consumers, their relationship to the product, and how they will access or interact with it. Finally, define how the data product will be delivered, including its format and interface.
Work iteratively and keep entries concise. The canvas is intended to support structured thinking and progressive refinement of your idea. If multiple ideas exist, complete a separate canvas for each data product concept.
Data-Driven Service Canvas
Use this canvas to further specify and structure your data-driven service idea. The goal is to gradually clarify how data create value within an ongoing service, who benefits from it, and how the idea translates into a concrete organizational application. Rather than focusing on technical architecture, the canvas supports a practice-oriented understanding of how data enable meaningful interactions, outcomes, and changes in everyday contexts.
Start by describing the service idea in simple and concise terms to capture what the service is about and why it exists. Then work through the service value section by outlining which organizational problem is addressed, who benefits from the service, what changes through its use, and which outcomes are expected. This step helps to sharpen the purpose of the service and makes its relevance more tangible.
Next, focus on the role of data in the service by identifying which data are used and what they enable, such as insights, monitoring, or decision support. Instead of describing technical systems, concentrate on how data shape the service process and contribute to value creation.
Continue with the service interaction area by outlining a short flow that explains what happens when someone engages with the service and what result or output is produced for the user.
Finally, use the scope and development section to reflect on what is already clear, what still requires clarification, and which next step could help to further specify the idea. Work iteratively and keep entries concise and practice-oriented. Use one canvas per service idea so that each concept can be developed and refined independently.

Model Training Canvas
Use this canvas to further specify and structure your model training idea. The goal is to clarify what the model should achieve, which data are required to train it, and how the resulting model creates value within an organizational context. Rather than focusing on technical details, the canvas supports a structured and practice-oriented reflection on how data are transformed into a trained analytical artifact.
Begin by describing the modeling objective in simple and concise terms. Specify what the model should predict, classify, or estimate and why this objective is relevant for your organization. Clearly define the target variable or outcome of interest.
Next, identify the required training and validation data. Reflect on whether the necessary data are conceptually available and sufficiently suitable for the intended modeling task. Then outline how model performance would be assessed, for example through accuracy, robustness, or other relevant criteria.
Continue by describing the intended deployment context. Explain how and where the trained model would be used and what role it would play within organizational processes or decision-making structures.
Finally, reflect briefly on governance and access considerations, including applicable EHDS pathways and secure processing requirements. Work iteratively and keep entries concise and practice-oriented. Use one canvas per model training idea so that each concept can be refined independently.

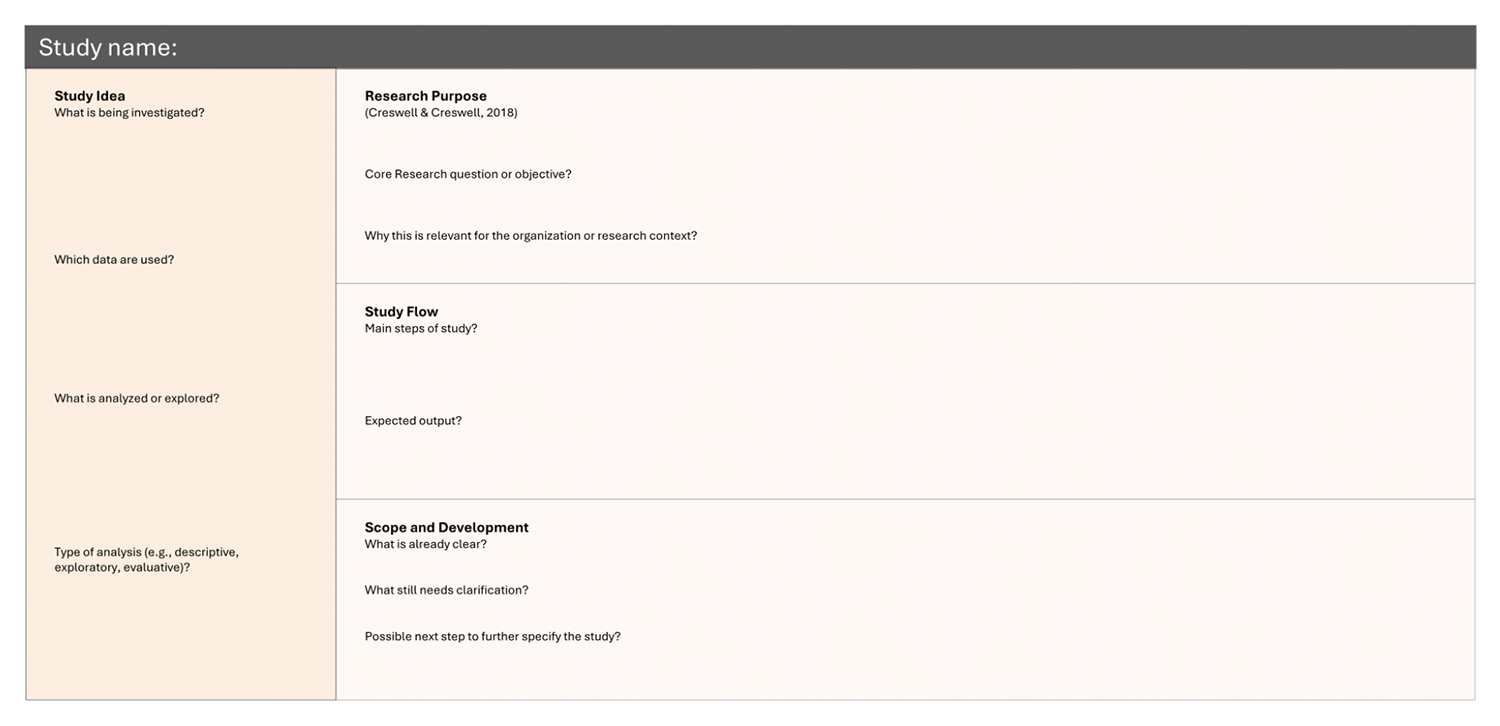
Study Canvas
Use this canvas to further specify a study idea by clarifying its analytical focus, research purpose, and expected knowledge outcome. The aim is not to design a full research protocol, but to gradually translate an initial idea into a structured and understandable study concept.
Start by describing the study idea and outlining which data are used and what is being investigated. Then formulate the research purpose by defining the core research question or objective and explaining why the study is relevant within the organizational or research context. Focus on the intended insight rather than methodological detail.
Next, describe the study flow by outlining the main analytical steps and the expected output, such as insights, reports, or evaluations. Use this section to make the analytical logic of the study visible. Finally, reflect on the scope and development by capturing what is already clear, what still requires clarification, and which next step could help further specify the study.
Work iteratively and keep entries concise. The canvas is intended to support structured thinking and the progressive concretization of study ideas. If several study concepts emerge, use separate canvases for each idea.
From concept to assessment
Once a use case has been specified in more concrete terms, organizations may begin to reflect more systematically on the suitability and characteristics of the underlying data. Depending on the intended purpose of use, different analytical methods may be relevant. The “Methods & Analytical Tools” section provides structured approaches for assessing data quality, governance implications, generative potential, and economic positioning.
If you want to take advantage of the opportunities created by the EHDS, you need to develop concrete ideas for how health data could support your organization. The ideation phase helps you translate the data types and initial use cases identified during exploration into organization-specific usage ideas.
At this stage, you focus on developing potential concepts for how data could be used in practice. You explore how specific datasets, potential use cases and possible access pathways could come together to support meaningful initiatives within your organizational context.
The goal of the ideation phase is not to evaluate or prioritize ideas yet. Instead, you develop a set of preliminary usage ideas that describe how health data could create value for your organization. These ideas form the basis for the next step, where you consolidate and further refine them.
References
Beam, A. L., & Kohane, I. S. (2018). Big data and machine learning in health care. New England Journal of Medicine, 378(26), 2507–2509. https://doi.org/10.1056/NEJMp1802070
Beverungen, D., Matzner, M., Janiesch, C., & Müller, O. (2019). Information systems for smart service systems. Information Systems Journal, 29(1), 3–10. https://doi.org/10.1111/isj.12222
Creswell, J. W., & Creswell, J. D. (2018). Research design: Qualitative, quantitative, and mixed methods approaches (5th ed.). SAGE Publications.
Dehghani, Z. (2022). Data mesh: Delivering data-driven value at scale. O’Reilly Media.
Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep learning. MIT Press.
Hasan, M. R., Finkel, B., & Legner, C. (2025). The data product canvas: Designing data products for sustained value from enterprise data. Information Systems Journal.
Hastie, T., Tibshirani, R., & Friedman, J. (2009). The elements of statistical learning: Data mining, inference, and prediction (2nd ed.). Springer.
Jordan, M. I., & Mitchell, T. M. (2015). Machine learning: Trends, perspectives, and prospects. Science, 349(6245), 255–260. https://doi.org/10.1126/science.aaa8415
Lim, C., & Maglio, P. P. (2018). Data-driven service innovation: A conceptual framework. Journal of Service Management, 29(3), 480–497. https://doi.org/10.1108/JOSM-01-2017-0008
Otto, B. (2011). Organizing data governance: Findings from the telecommunications industry and consequences for large service providers. Communications of the Association for Information Systems, 29, Article 3.
Shmueli, G. (2010). To explain or to predict? Statistical Science, 25(3), 289–310. https://doi.org/10.1214/10-STS330